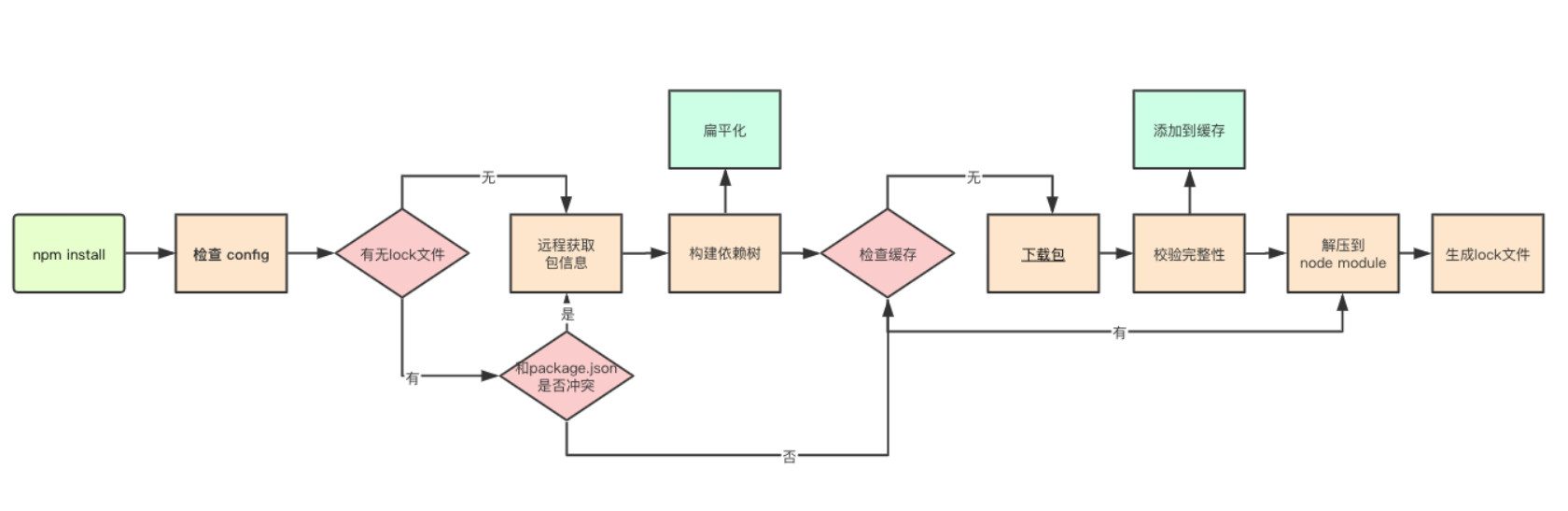
这里主要参考的是nodejs的主要内容参考,后面再补充阅读深入浅出Nodejs
小基础 -V8引擎
这里V8没有深入地写,这里我理解V8为解析执行的js的引擎(用于chorm,nodejs)
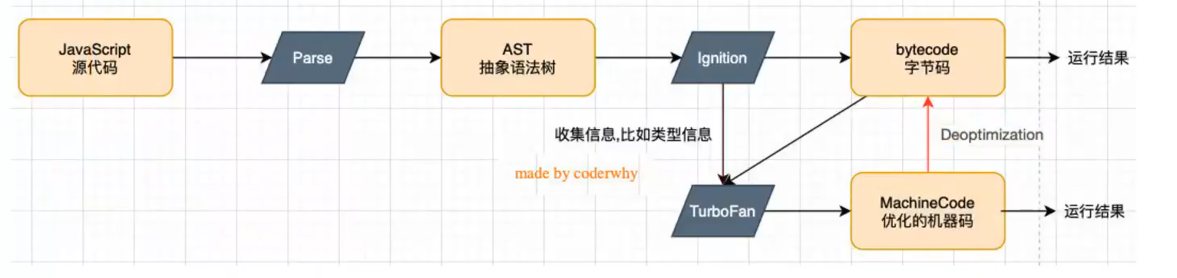
这里其实有一个拓展的东西,就是关于ts 为什么更好。 这里有一个deoptimization。 这里就是当输入没有进行处理(以往都是int,突然来了string) 这样就会出现重新逆向转换字节码,然后再次处理。 但是ts呢,就可以提前固定~~
那么node 跟 浏览器有什么区别呢?
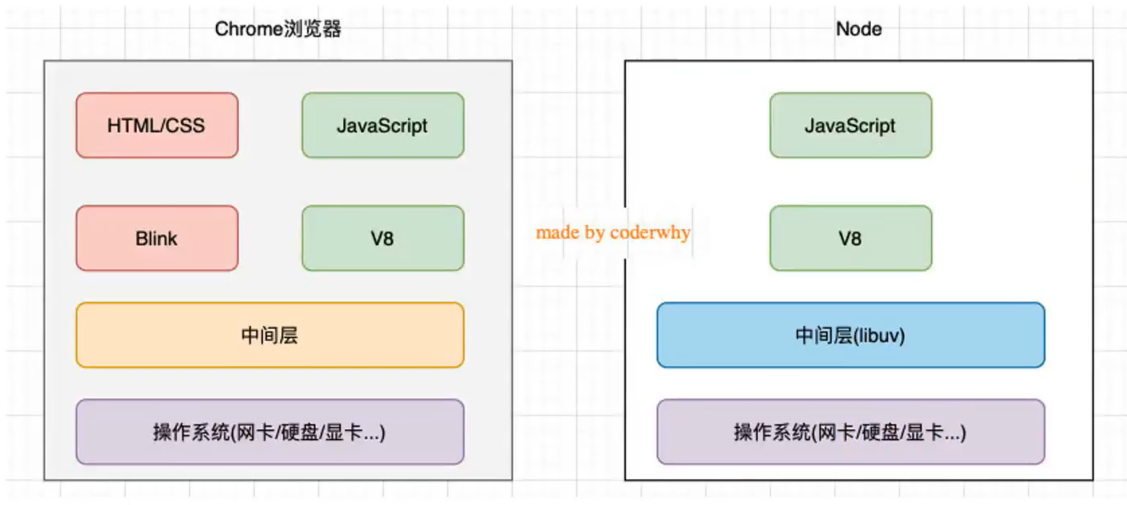
nodejs 角色
这里我个人认为整个的意识很重要,也就是nodejs 作为什么东西
Node 是什么
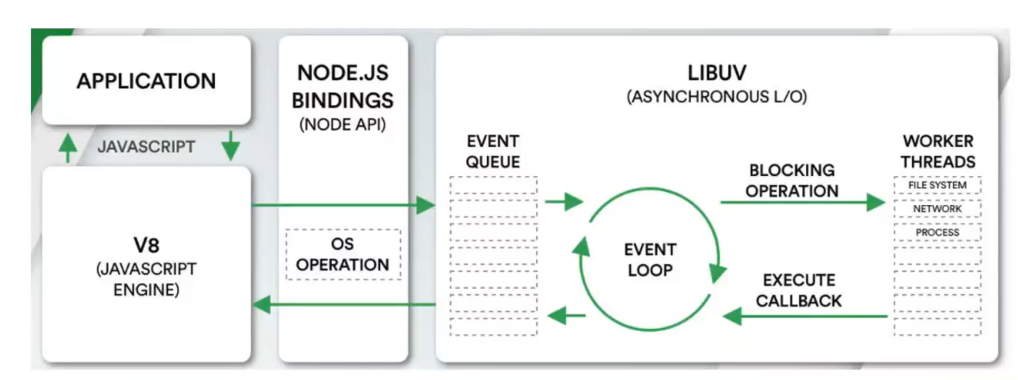
Node.js 是异步的、事件驱动的、非阻塞的和单线程的running environment!! 最主要得是提供http server 以及对于文件处理
注意!! nodejs 不是编程语言,也不是framework
Node回调函数 阻塞&非阻塞 异步&同步
同步:同步就是你要做的事你列了一个清单,按照清单上的顺序 一个一个执行
异步:就是可以同时干好几件事
阻塞:就是按照清单上的顺序一件一件的往下走,当一件事没有做完,下面的事都干不了
非阻塞:就是这件事没有干完,后面的事不会等你这件事干完了再干,而是直接开始干下一件事,等你这件事干完了,后面的事也干完了,这样就大大提高了效率
所以 这里我们理解一下nodejs 是怎么运行的:
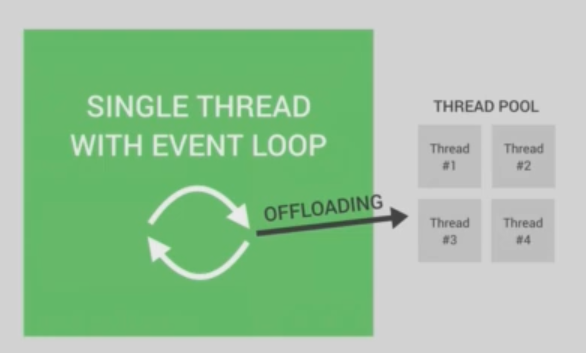
- nodejs 是单线程,所以他会管理多个task
- 同时也要listen to event queue
- 所以对于node,比较合适 real time I/O intensive APP ,而不是 CPU intensive APP
异步函数例子
var fs = require("fs");
fs.readFile('input.txt', function (err, data) {
if (err){
console.log(err.stack);
return;
}
console.log(data.toString());
});
console.log("程序执行完毕");Node.js 事件循环
Node.js 使用事件驱动模型,当web server接收到请求,就把它关闭然后进行处理,然后去服务下一个web请求。当这个请求完成,它被放回处理队列,当到达队列开头,这个结果被返回给用户。
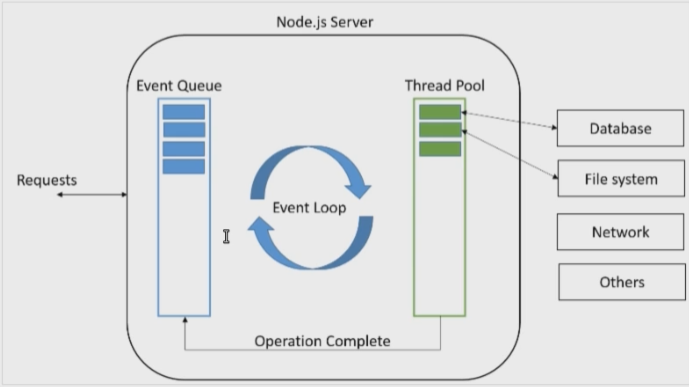
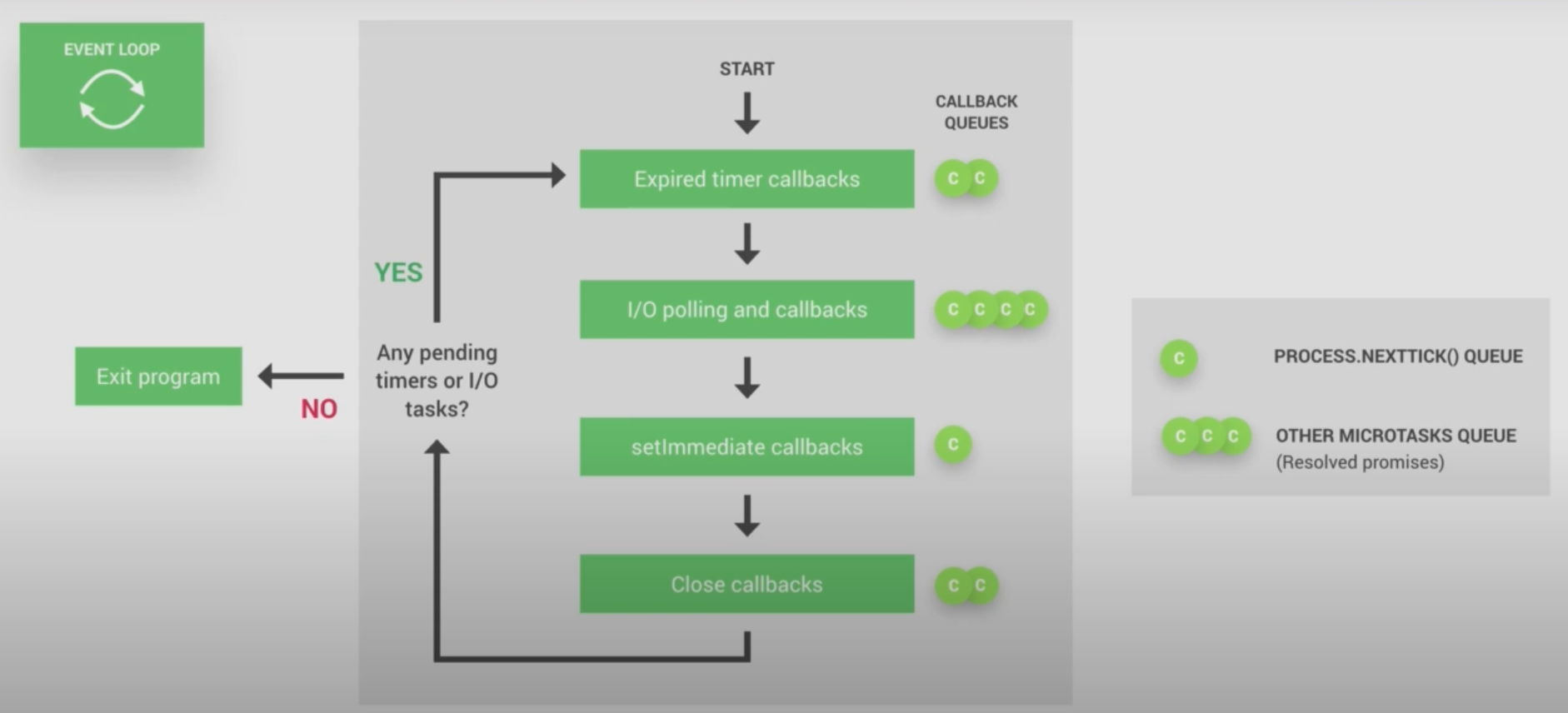
//每个框被称为事件循环机制的一个阶段
┌───────────────────────────┐
┌─>│ timers │
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
│ │ pending callbacks │
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
│ │ idle, prepare │
│ └─────────────┬─────────────┘ ┌───────────────┐
│ ┌─────────────┴─────────────┐ │ incoming: │
│ │ poll │<─────┤ connections, │
│ └─────────────┬─────────────┘ │ data, etc. │
│ ┌─────────────┴─────────────┐ └───────────────┘
│ │ check │
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
└──┤ close callbacks │
└───────────────────────────┘- timers: this phase executes callbacks scheduled by
setTimeout()andsetInterval(). - pending callbacks: executes I/O callbacks deferred to the next loop iteration. (I/O callbacks 也就是readFile 啥的)
- idle, prepare: only used internally.
- poll: retrieve new I/O events; execute I/O related callbacks (almost all with the exception of close callbacks, the ones scheduled by timers, and
setImmediate()); node will block here when appropriate. - check:
setImmediate()callbacks are invoked here. - close callbacks: some close callbacks, e.g.
socket.on('close', ...).
这里肯定会想到js 得运行 对不对,这里建议看看这里IBM 教程 文字版资料
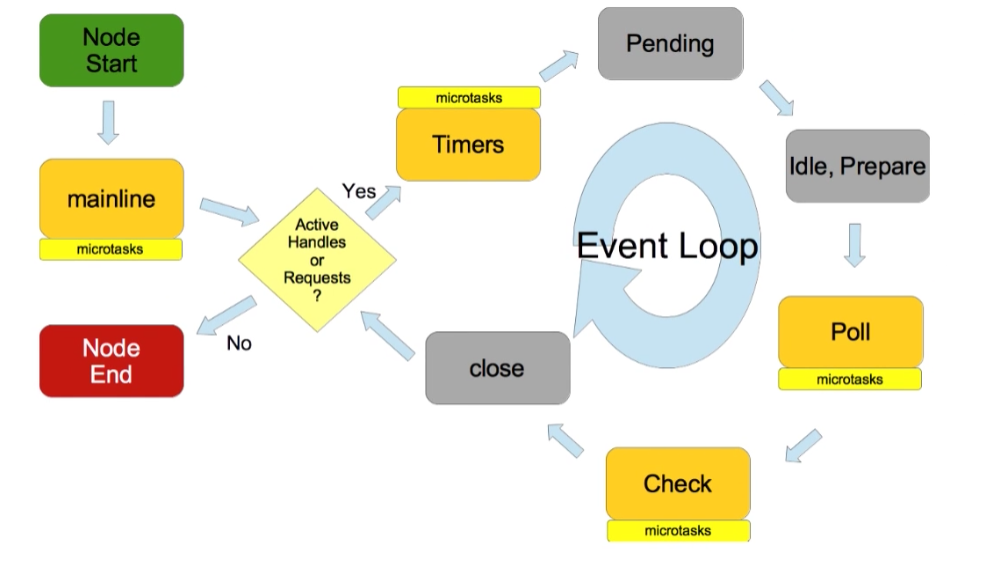
microtasks are callbacks from:
process.nextTick()then()handlers for resolved or rejected Promises
nodejs 事件循环自测
答案请参考https://developer.ibm.com/tutorials/learn-nodejs-the-event-loop/
//关于process.nexttick()
//这里最需要注意的
const fs = require("fs");
const logger = require("../common/logger");
const ITERATIONS_MAX = 2;
let iteration = 0;
process.nextTick(() => {
logger.info("process.nextTick", "MAINLINE MICROTASK");
});
logger.info("START", "MAINLINE");
const timeout = setInterval(() => {
logger.info("START iteration " + iteration + ": setInterval", "TIMERS PHASE");
if (iteration < ITERATIONS_MAX) {
setTimeout(
(iteration) => {
logger.info(
"TIMER EXPIRED (from iteration " +
iteration +
"): setInterval.setTimeout",
"TIMERS PHASE"
);
process.nextTick(() => {
logger.info(
"setInterval.setTimeout.process.nextTick",
"TIMERS PHASE MICROTASK"
);
});
},
0,
iteration
);
fs.readdir("../data", (err, files) => {
logger.info(
"fs.readdir() callback: Directory contains: " + files.length + " files",
"POLL PHASE"
);
process.nextTick(() => {
logger.info(
"setInterval.fs.readdir.process.nextTick",
"POLL PHASE MICROTASK"
);
});
});
setImmediate(() => {
logger.info("setInterval.setImmediate", "CHECK PHASE");
process.nextTick(() => {
logger.info(
"setInterval.setTimeout.process.nextTick",
"CHECK PHASE MICROTASK"
);
});
});
} else {
logger.info("Max interval count exceeded. Goodbye.", "TIMERS PHASE");
clearInterval(timeout);
}
logger.info("END iteration " + iteration + ": setInterval", "TIMERS PHASE");
iteration++;
}, 0);
logger.info("MAINLINE: END");输出:
1530401857782:INFO: MAINLINE: START
1530401857784:INFO: MAINLINE: END
1530401857785:INFO: MAINLINE MICROTASK: process.nextTick
1530401857786:INFO: TIMERS PHASE: START iteration 0: setInterval
1530401857786:INFO: TIMERS PHASE: END iteration 0: setInterval
1530401857787:INFO: POLL PHASE: fs.readdir() callback: Directory contains: 8 files
1530401857787:INFO: POLL PHASE MICROTASK: setInterval.fs.readdir.process.nextTick
1530401857787:INFO: CHECK PHASE: setInterval.setImmediate
1530401857787:INFO: CHECK PHASE MICROTASK: setInterval.setTimeout.process.nextTick
1530401857787:INFO: TIMERS PHASE: TIMER EXPIRED (from iteration 0): setInterval.setTimeout
1530401857787:INFO: TIMERS PHASE: START iteration 1: setInterval
1530401857788:INFO: TIMERS PHASE: END iteration 1: setInterval
1530401857788:INFO: TIMERS PHASE MICROTASK: setInterval.setTimeout.process.nextTick
1530401857788:INFO: POLL PHASE: fs.readdir() callback: Directory contains: 8 files
1530401857788:INFO: POLL PHASE MICROTASK: setInterval.fs.readdir.process.nextTick
1530401857788:INFO: CHECK PHASE: setInterval.setImmediate
1530401857788:INFO: CHECK PHASE MICROTASK: setInterval.setTimeout.process.nextTick
1530401857788:INFO: TIMERS PHASE: TIMER EXPIRED (from iteration 1): setInterval.setTimeout
1530401857788:INFO: TIMERS PHASE: START iteration 2: setInterval
1530401857788:INFO: TIMERS PHASE: Max interval count exceeded. Goodbye.
1530401857788:INFO: TIMERS PHASE: END iteration 2: setInterval
1530401857788:INFO: TIMERS PHASE MICROTASK: setInterval.setTimeout.process.nextTickAfter each event loop phase, there is a process.nextTick() delimiter callback to mark the end of that phase. Since you know the phase delimiter callback MUST run after that phase, whatever output follows MUST be coming from a subsequent phase of the event loop.
EventEmitter
首先要理解eventEmitter是一个class, 每次都要实例化,然后用这个新的obj通过on emit进行操作
EventEmitter 的核心就是事件触发与事件监听器功能的封装。这里我理解为引入模块,然后对时间进行实例化,通过增加名字,达到一个时间监听。
//event.js 文件
var events = require('events');
var emitter = new events.EventEmitter();
emitter.on('someEvent', function(arg1, arg2) {
console.log('listener1', arg1, arg2);
});
emitter.on('someEvent', function(arg1, arg2) {
console.log('listener2', arg1, arg2);
});
emitter.emit('someEvent', 'arg1 参数', 'arg2 参数');
//$ node event.js
//listener1 arg1 参数 arg2 参数
//listener2 arg1 参数 arg2 参数
//Es6中class extends的办法写
const EventEmitter = require('events');
class MyEmitter extends EventEmitter {
// Add any custom methods here
}
const myEmitter = new MyEmitter();
myEmitter.on('event', () => {
console.log('an event occurred!');
});
myEmitter.emit('event');增加监听的方式有两种:
eventEmitter.addListener('connection', listener1);eventEmitter.on('connection', listener2);eventEmitter.on()与eventEmitter.addListener()没有区别,且一个事件可以绑定多个回调函数;
若事件队列中出现一个未绑定事件则触发error事件,若未绑定 error事件则程序抛出异常结束执行
EventEmitter 里面的 error 事件,EventEmitter 即使绑定了 error 事件,也是不会输出的。而是会在控制台打印该异常的堆栈信息,并结束进程。 获取异常只能通过 try catch。
eventEmitter.on('error',function(err){
console.error('Error:',err);
});我测试了一下,绑定 error 事件。只能自己触发,eventEmitter.emit(‘error’); 当没有错误时,会在控制台打印 Error:undefined。有错误时,不会打印,直接打印该异常的堆栈信息,并结束进程。
Buffer(缓冲区)
这部分还没有实战过~ sorry
Buffer 类用来创建一个专门存放二进制数据的缓存区(文字 数字 图片 音频)。
对于视频而言,一般最好大于16帧/s(低于16 肉眼会觉得卡顿)
Stream(流)
流(Stream)是基于 EventEmitter的数据管理模式,由各种不同的抽象接口组成,主要包括可写、可读、可读写、可转换等类型。
Stream 有四种流类型:
- Readable - 可读操作。
- Writable - 可写操作。
- Duplex - 可读可写操作.
- Transform - 操作被写入数据,然后读出结果。
所有的 Stream 对象都是 EventEmitter 的实例。常用的事件有:
- data - 当有数据可读时触发。
- end - 没有更多的数据可读时触发。
- error - 在接收和写入过程中发生错误时触发。
- finish - 所有数据已被写入到底层系统时触发。
- 读取流
fs.createReadStream('input.txt'); - 写入流
fs.createWriteStream('output.txt'); - 管道流
readerStream.pipe(writerStream); - 链式流
var fs = require("fs");
var zlib = require('zlib');
// 压缩 input.txt 文件为 input.txt.gz
fs.createReadStream('input.txt')
.pipe(zlib.createGzip())
.pipe(fs.createWriteStream('input.txt.gz'));
console.log("文件压缩完成。");node js模块化
这里回忆一下CMD,关键词 require module.exports exports
这里思考一下 exports 是什么 ? 是一个对象,也就是引用类型,也就是浅层拷贝。
另外 module.exports是什么呢?
每一个文件 作为模块,都会new 一个 module。每一次exports 实际上都是module.exports 实现的。 那为什么这两个用起来一样呢,因为源码里面 exports = module.exports(都是引用类)
node 模块
- http、fs、path等,原生模块。
- ./mod或../mod,相对路径的文件模块。
- /pathtomodule/mod,绝对路径的文件模块。
- mod,非原生模块的文件模块。
这里 练习一下commonjs 的 module.exports 文件的导入导出~
来源于菜鸟~
不建议同时使用 exports 和 module.exports。
如果先使用 exports 对外暴露属性或方法,再使用 module.exports 暴露对象,会使得 exports 上暴露的属性或者方法失效。
原因在于,exports 仅仅是 module.exports 的一个引用。在 nodejs 中,是这么设计 require 函数的:
function require(...){
var module = {exports: {}};
((module, exports) => {
function myfn () {}
// 这个myfn就是我们自己的代码
exports.myfn = myfn; // 这里是在原本的对象上添加了一个myfn方法。
module.exports = myfn;// 这个直接把当初的对象进行覆盖。
})(module,module.exports)
return module.exports;
}router
node 变量对象
_ 下划线代表当前。 比如__filename 表示当前正在执行的脚本的文件名
process 是一个全局变量,即 global 对象的属性
剩下的看api吧
Node.js 常用工具 util
util 是一个Node.js 核心模块,提供常用函数的集合,用于弥补核心 JavaScript 的功能 过于精简的不足。
util.callbackify(original) 将
async异步函数(或者一个返回值为Promise的函数)转换成遵循异常优先的回调风格的函数,例如将(err, value) => ...回调作为最后一个参数。 在回调函数中,第一个参数为拒绝的原因(如果Promise解决,则为null),第二个参数则是解决的值util.inherits(constructor, superConstructor) 是一个实现对象间原型继承的函数。
util.inspect(object,[showHidden],[depth],[colors]) 是一个将任意对象转换 为字符串的方法,通常用于调试和错误输出。它至少接受一个参数 object,即要转换的对象。
util.isArray(object) 如果给定的参数 “object” 是一个数组返回 true,否则返回 false。
util.isRegExp(object) 如果给定的参数 “object” 是一个正则表达式返回true,否则返回false
**util.isDate(object) ** 如果给定的参数 “object” 是一个日期返回true,否则返回false。
node 参数 process.argv[]
GET/POST请求
process.nextTick()
process.nextTick()方法,会将回调函数放入队列中,在下一轮Tick时取出执行
setImmediate()与nexttick方法类似,都是将回调函数延迟执行,但process.nextTick()中的回调函数执行优先级高于setImmediate()

process.nextTick() 对比 setImmediate()
就用户而言,我们有两个类似的调用,但它们的名称令人费解。
process.nextTick()在同一个阶段立即执行。setImmediate()在事件循环的接下来的迭代或 ‘tick’ 上触发。
实质上,这两个名称应该交换,因为 process.nextTick() 比 setImmediate() 触发得更快,但这是过去遗留问题,因此不太可能改变。如果贸然进行名称交换,将破坏 npm 上的大部分软件包。每天都有更多新的模块在增加,这意味着我们要多等待每一天,则更多潜在破坏会发生。尽管这些名称使人感到困惑,但它们本身名字不会改变。
下面的内容是
看官网以及书(有点干&无聊)
Path
node 中的路径分类
node 中的路径大致分 5 类,dirname,filename,process.cwd(),./,../,其中dirname,filename,process.cwd()绝对路径
- dirname: 总是返回被执行的 js 所在文件夹的绝对路径
- filename: 总是返回被执行的 js 的绝对路径
- process.cwd(): 总是返回运行 node 命令时所在的文件夹的绝对路径
./: 不使用 require 时候,./与process.cwd()一样,使用require时候,与__dirname一样
只有在 require() 时才使用相对路径(./, ../) 的写法,其他地方一律使用绝对路径,如下:
// 当前目录下
path.dirname(__filename) + '/path.js'
// 相邻目录下
path.resolve(__dirname, '../regx/regx.js')API
path.normalize(p)
规范化一个字符串路径,照顾'..'和'.'部分。
当找到多个斜线时,它们会被一个斜线替换;当路径包含尾部斜杠时,它会被保留。在 Windows 上使用反斜杠。
path.resolve([from …], to)
解析to为绝对路径。
If tois not already absolutefrom参数按从右到左的顺序添加,直到找到绝对路径。如果使用所有from路径后仍然没有找到绝对路径,则也使用当前工作目录。生成的路径被规范化,除非路径被解析到根目录,否则会删除尾部斜杠。非字符串from参数将被忽略。
另一种方式是将其视为cdshell 中的一系列命令。
path.dirname(p)
返回路径的目录名称。类似于 Unixdirname命令。
举例说明
const path = require('path')
console.log(path.resolve('/foo/bar', '/bar/faa', '..', 'a/../c'));/bar/c作用 相当于cd
path.join
path.join([…paths])
- 传入的参数是字符串的路径片段,可以是一个,也可以是多个
- 返回的是一个拼接好的路径,
path.parse
他返回的是一个对象,那么我们来把这么几个名词熟悉一下:
- root:代表根目录
- dir:代表文件所在的文件夹
- base:代表整一个文件
- name:代表文件名
- ext: 代表文件的后缀名
path.basename
basename 接收两个参数,第一个是path,第二个是ext(可选参数),当输入第二个参数的时候,打印结果不出现后缀名
path.extname
返回的是后缀名,但是最后两种情况(文件夹)返回’’,大家注意一下。
path.relative
path.relative(from, to)
描述:从 from 路径,到 to 路径的相对路径。
边界:
- 如果 from、to 指向同个路径,那么,返回空字符串。
- 如果 from、to 中任一者为空,那么,返回当前工作路径
fs模块
Node.js 中的 fs 模块是文件操作的封装,它一共以下几个部分
(1) POSIX文件 Wrapper,对应操作系统的原生文件操作。
(2)文件流,fs. createReadStream和 fs.createWriteStrean。
(3)同步文件读写, fs.readFileSync和fs.writeFileSync。
(4)异步文件读写, fs.readFile和fs.writeFile。
与其它模块不同的是,fs 模块中所有的操作都提供了异步和同步的两个版本,具有 sync 后缀的方法为同步方法,不具有 sync 后缀的方法为异步方法
基本文件操作知识
权限位 mode
因为 fs 模块需要对文件进行操作,会涉及到操作权限的问题,所以需要先清楚文件权限是什么,都有哪些权限。
文件权限表:
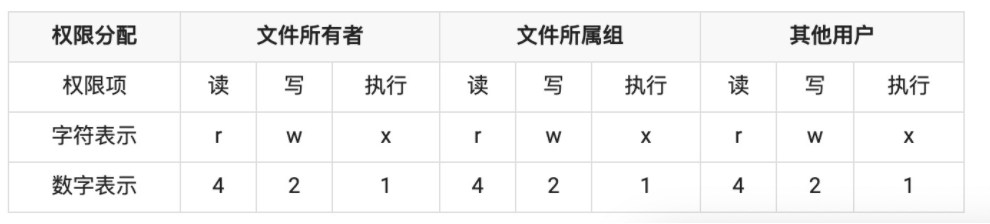
在上面表格中,我们可以看出系统中针对三种类型进行权限分配,即文件所有者(自己)、文件所属组(家人)和其他用户(陌生人),文件操作权限又分为三种,读、写和执行,数字表示为八进制数,具备权限的八进制数分别为 4、2、1,不具备权限为 0。
为了更容易理解,我们可以随便在一个目录中打开 Git,使用 Linux 命令 ls -al 来查目录中文件和文件夹的权限位
drwxr-xr-x 1 koala 197121 0 Jun 28 14:41 core
-rw-r--r-- 1 koala 197121 293 Jun 23 17:44 index.md在上面的目录信息当中,很容易看出用户名、创建时间和文件名等信息,但最重要的是开头第一项(十位的字符)。
第一位代表是文件还是文件夹,d 开头代表文件夹,- 开头的代表文件,而后面九位就代表当前用户、用户所属组和其他用户的权限位,按每三位划分,分别代表读(r)、写(w)和执行(x),- 代表没有当前位对应的权限。
权限参数 mode 主要针对 Linux 和 Unix 操作系统,Window 的权限默认是可读、可写、不可执行,所以权限位数字表示为 0o666,转换十进制表示为 438。

标识位 flag
Node.js 中,标识位代表着对文件的操作方式,如可读、可写、即可读又可写等等,在下面用一张表来表示文件操作的标识位和其对应的含义。
| 符号 | 含义 |
|---|---|
| r | 读取文件,如果文件不存在则抛出异常。 |
| r+ | 读取并写入文件,如果文件不存在则抛出异常。 |
| rs | 读取并写入文件,指示操作系统绕开本地文件系统缓存。 |
| w | 写入文件,文件不存在会被创建,存在则清空后写入。 |
| wx | 写入文件,排它方式打开。 |
| w+ | 读取并写入文件,文件不存在则创建文件,存在则清空后写入。 |
| wx+ | 和 w+ 类似,排他方式打开。 |
| a | 追加写入,文件不存在则创建文件。 |
| ax | 与 a 类似,排他方式打开。 |
| a+ | 读取并追加写入,不存在则创建。 |
| ax+ | 与 a+ 类似,排他方式打开。 |
上面表格就是这些标识位的具体字符和含义,但是 flag 是不经常使用的,不容易被记住,所以在下面总结了一个加速记忆的方法。
- r:读取
- w:写入
- s:同步
- +:增加相反操作
- x:排他方式
r+ 和 w+ 的区别,当文件不存在时,r+ 不会创建文件,而会抛出异常,但 w+ 会创建文件;如果文件存在,r+ 不会自动清空文件,但 w+ 会自动把已有文件的内容清空。
fs 文件操作
完整性读写文件操作
文件读取-fs.readFile
fs.readFile(filename,[encoding],[callback(error,data)]文件读取函数
- 它接收第一个必选参数 filename,表示读取的文件名。
- 第二个参数 encoding 是可选的,表示文件字符编码。
- 第三个参数
callback是回调函数,用于接收文件的内容。 说明:如果不指定 encoding ,则callback就是第二个参数。 回调函数提供两个参数 err 和 data , err 表示有没有错误发生,data 是文件内容。 如果指定 encoding , data 是一个解析后的字符串,否则将会以 Buffer 形式表示的二进制数据。
demo:
const fs = require('fs')
const path = require('path')
const filePath = path.join(__dirname, 'koalaFile.txt')
const filePath1 = path.join(__dirname, 'koalaFile1.txt')
// -- 异步读取文件
fs.readFile(filePath, 'utf8', function(err, data) {
console.log(data) // coding
})
// -- 同步读取文件
const fileResult = fs.readFileSync(filePath, 'utf8')
console.log(fileResult) 文件写入 fs.writeFile
fs.writeFile(filename, data, [options], callback)文件写入操作
- 第一个必选参数 filename ,表示读取的文件名
- 第二个参数要写的数据
- 第三个参数 option 是一个对象,如下
encoding {String | null} default='utf-8'
mode {Number} default=438(aka 0666 in Octal)
flag {String} default='w'
这个时候第一章节讲的计算机知识就用到了,flag 值,默认为 w,会清空文件,然后再写。flag 值,r 代表读取文件,w 代表写文件,a 代表追加。
demo:
// 写入文件内容(如果文件不存在会创建一个文件)
// 写入时会先清空文件
fs.writeFile(filePath, '写入成功:coding', function(err) {
if (err) {
throw err
}
// 写入成功后读取测试
var data = fs.readFileSync(filePath, 'utf-8')
console.log('new data -->' + data)
})
// 通过文件写入并且利用flag也可以实现文件追加
fs.writeFile(filePath, 'coding追加的数据', { 'flag': 'a' }, function(
err
) {
if (err) {
throw err
}
console.log('success')
var data = fs.readFileSync(filePath, 'utf-8')
// 写入成功后读取测试
console.log('追加后的数据 -->' + data)
})文件追加-appendFile
fs.appendFile(filename, data, [options], callback)- 第一个必选参数 filename ,表示读取的文件名
- 第二个参数 data,data 可以是任意字符串或者缓存
- 第三个参数 option 是一个对象,与 write 的区别就是[options]的 flag 默认值是”a”,所以它以追加方式写入数据.
说明:该方法以异步的方式将 data 插入到文件里,如果文件不存在会自动创建
demo:
// -- 异步另一种文件追加操作(非覆盖方式)
// 写入文件内容(如果文件不存在会创建一个文件)
fs.appendFile(filePath, '新数据coding456', function(err) {
if (err) {
throw err
}
// 写入成功后读取测试
var data = fs.readFileSync(filePath, 'utf-8')
console.log(data)
})
// -- 同步另一种文件追加操作(非覆盖方式)
fs.appendFileSync(filePath, '同步追加一条新数据coding789')拷贝文件-copyFile
fs.copyFile(filenameA, filenameB,callback)- 第一个参数原始文件名
- 第二个参数要拷贝到的文件名 demo:
// 将filePath文件内容拷贝到filePath1文件内容
fs.copyFileSync(filePath, filePath1);
let data = fs.readFileSync(filePath1, 'utf8');
console.log(data); // coding
删除文件-unlink
fs.unlink(filename, callback) - 第一个参数文件路径大家应该都知道了,后面我就不重复了
- 第二个回调函数 callback
demo:
// -- 异步文件删除
fs.unlink(filePath, function(err) {
if (err) return
})
// -- 同步删除文件
fs.unlinkSync(filePath, function(err) {
if (err) return
})指定位置读写文件操作(高级文件操作)
接下来的高级文件操作会与上面有些不同,流程稍微复杂一些,要先用fs.open来打开文件,然后才可以用fs.read去读,或者用fs.write去写文件,最后,你需要用fs.close去关掉文件。
特殊说明:read 方法与 readFile 不同,一般针对于文件太大,无法一次性读取全部内容到缓存中或文件大小未知的情况,都是多次读取到 Buffer 中。 想了解 Buffer 可以看 NodeJS —— Buffer 解读。(注意这里换成我的文章)
文件打开-fs.open
fs.open(path, flags, [mode], callback)第一个参数:文件路径 第二个参数:与开篇说的标识符 flag 相同 第三个参数:[mode] 是文件的权限(可选参数,默认值是 0666) 第四个参数:callback 回调函数
demo:
fs.open(filePath, 'r', '0666', function(err, fd) {
console.log('哈哈哈', fd) //返回的第二个参数为一个整数,表示打开文件返回的文件描述符,window中又称文件句柄
})demo 说明:返回的第二个参数为一个整数,表示打开文件返回的文件描述符,window 中又称文件句柄,在开篇也有对文件描述符说明。
文件读取-fs.read
fs.read(fd, buffer, offset, length, position, callback)六个参数
- fd:文件描述符,需要先使用 open 打开,使用
fs.open打开成功后返回的文件描述符; - buffer:一个 Buffer 对象,
v8引擎分配的一段内存,要将内容读取到的 Buffer; - offset:整数,向 Buffer 缓存区写入的初始位置,以字节为单位;
- length:整数,读取文件的长度;
- position:整数,读取文件初始位置;文件大小以字节为单位
- callback:回调函数,有三个参数 err(错误),bytesRead(实际读取的字节数),buffer(被写入的缓存区对象),读取执行完成后执行。
demo:
const fs = require('fs')
let buf = Buffer.alloc(6) // 创建6字节长度的buf缓存对象
// 打开文件
fs.open('6.txt', 'r', (err, fd) => {
// 读取文件
fs.read(fd, buf, 0, 3, 0, (err, bytesRead, buffer) => {
console.log(bytesRead)
console.log(buffer)
// 继续读取
fs.read(fd, buf, 3, 3, 3, (err, bytesRead, buffer) => {
console.log(bytesRead)
console.log(buffer)
console.log(buffer.toString())
})
})
})
// 3
// <Buffer e4 bd a0 00 00 00>
// 3
// <Buffer e4 bd a0 e5 a5 bd>
// 你好文件写入-fs.write
fs.write(fd, buffer, offset, length, position, callback)六个参数
- fd:文件描述符,使用
fs.open打开成功后返回的; - buffer:一个 Buffer 对象,
v8引擎分配的一段内存,存储将要写入文件数据的 Buffer; - offset:整数,从 Buffer 缓存区读取数据的初始位置,以字节为单位;
- length:整数,读取 Buffer 数据的字节数;
- position:整数,写入文件初始位置;
- callback:写入操作执行完成后回调函数,有三个参数 err(错误),bytesWritten(实际写入的字节数),buffer(被读取的缓存区对象),写入完成后执行。
文件关闭-fs.close
fs.close(fd, callback)- 第一个参数:fd 文件
open时传递的文件描述符 - 第二个参数 callback 回调函数,回调函数有一个参数 err(错误),关闭文件后执行。
demo:
// 注意文件描述符fd
fs.open(filePath, 'r', (err, fd) => {
fs.close(fd, (err) => {
console.log('关闭成功') // 关闭成功
})
})fs目录(文件夹)操作
1、fs.mkdir 创建目录
fs.mkdir(path, [options], callback)- 第一个参数:path 目录路径
- 第二个参数[options],
recursive <boolean>默认值: false。mode <integer>Windows 上不支持。默认值: 0o777。 可选的 options 参数可以是指定模式(权限和粘滞位)的整数,也可以是具有 mode 属性和 recursive 属性(指示是否应创建父文件夹)的对象。 - 第三个参数回调函数,回调函数有一个参数 err(错误),关闭文件后执行。
demo:
fs.mkdir('./mkdir', function(err) {
if (err) return
console.log('创建目录成功')
})注意: 在 Windows 上,在根目录上使用 fs.mkdir() (即使使用递归参数)也会导致错误:
fs.mkdir('/', { recursive: true }, (err) => {
// => [Error: EPERM: operation not permitted, mkdir 'C:\']
})2、fs.rmdir 删除目录
fs.rmdir(path, callback)- 第一个参数:path 目录路径
- 第三个参数回调函数,回调函数有一个参数 err(错误),关闭文件后执行。 demo:
const fs = require('fs')
fs.rmdir('./mkdir', function(err) {
if (err) return
console.log('删除目录成功')
})注意:在文件(而不是目录)上使用 fs.rmdir() 会导致在 Windows 上出现 ENOENT 错误、在 POSIX 上出现 ENOTDIR 错误。
3、fs.readdir 读取目录
fs.readdir(path, [options], callback)- 第一个参数:path 目录路径
- 第二个参数[options]可选的 options 参数可以是指定编码的字符串,也可以是具有 encoding 属性的对象,该属性指定用于传给回调的文件名的字符编码。 如果 encoding 设置为 ‘buffer’,则返回的文件名是 Buffer 对象。 如果 options.withFileTypes 设置为 true,则 files 数组将包含 fs.Dirent 对象。
- 第三个参数回调函数,回调函数有两个参数,第一个 err(错误),第二个返回 的 data 为一个数组,包含该文件夹的所有文件,是目录中的文件名的数组(不包括
'.'和'..')
url模块
在头部输入以下代码: const url = require("url");
url模块提供的方法
url模块目前提供三个方法url.parse(),url.format(),url.resolve();
url.parse(urlStr,[boolean],[boolean])
接口作用:解析一个url地址,返回一个url对象
参数:第一个参数 url地址字符串,第二个参数 为布尔值,默认false,当值为true,返回的url对象中query属性返回的是一个对象,第三个参数 为布尔值,默认false,如果设为 true,则//之后至下一个/之前的字符串会解析作为host.例如,//foo/bar会解析为{host:’foo’,pathname:’/bar’} 而不是 {pathname:’//foo/bar’}.
示例代码:
let parseUrl = "https://www.google.com?q=node.js";
let urlObj = url.parse(parseUrl,true);
console.log(urlObj);返回:
PS E:\项目\nodejs> node url.js
Url {
protocol: 'https:',
slashes: true,
auth: null,
host: 'www.google.com',
port: null,
hostname: 'www.google.com',
hash: null,
search: '?q=node.js',
query: [Object: null prototype] { q: 'node.js' },
pathname: '/',
path: '/?q=node.js',
href: 'https://www.google.com/?q=node.js' }url.format(urlObj)
接口作用:接受一个url对象,返回一个url字符串
参数:第一个参数 是一个url对象,具体参数见代码
示例代码:
let urlObj = {
protocol: 'https:',
slashes: true,
auth: null,
host: 'www.google.com',
port: null,
hostname: 'www.google.com',
hash: null,
search: '?q=node.js',
query: '?q=node.js',
pathname: '/',
path: '/?q=node.js',
};
let objFormatUrl = url.format(urlObj);
console.log(objFormatUrl);
返回:
PS E:\项目\nodejs> node url.js
https://www.google.com/?q=node.jsurl.resolve(from,to)
接口作用:拼接字符串网址
参数:第一个参数 拼接时相对的基本URL,第二个参数 要拼接的另一个url.
示例代码:
let urlAddress = url.resolve("https://www.google.com","image");
console.log(urlAddress);node - HTTP
我们需要搭建一个 http 的服务器,用于处理用户发送的 http 请求,在 node 中有 http 核心模块可以在很简单的几句话就帮我们启动一个服务器。
// 导入http模块:
var http = require('http');
// 创建http server,并传入回调函数:
var server = http.createServer(function (request, response) {
// 回调函数接收request和response对象,
console.log('有客户端请求了.....');
// 将HTTP响应200写入response, 同时设置Content-Type: text/html:
response.writeHead(200, {'Content-Type': 'text/html'});
// 将HTTP响应的HTML内容写入response:
response.write('<h1>hello World!</h1>');
response.end();
});
// 让服务器监听8888端口:
server.listen(8888,()=>{
console.log('Server is running at http://127.0.0.1:8888/');
});
就这几行代码,我们就搭建了一个简单服务器,当HTTP
创建与监听
首先我们来看创建http server的代码:
var server = http.createServer([requestListener]):创建并返回一个HTTP服务器对象 (这里实际上也就 new http.server() )requestListener: 监听到客户端连接的回调函数
在这里可以看到我们的回调函数是可选的,我们还可以使用事件监听器来进行,监听到客户端连接之后的操作,如:
server.on('request', function(req, res) {// do ....})
我们要在用户访问时做一些什么,都会在这里。
再看监听端口的代码
server.listen(port, [hostname], [backlog], [callback]):监听客户端连接请求,只有当调用了listen方法以后,服务器才开始工作port: 监听的端口hostname: 主机名(IP/域名),可选backlog: 连接等待队列的最大长度,可选callback: 调用listen方法并成功开启监听以后,会触发一个 listening事件,callback将作为该事件的执行函数,可选
看完了创建与监听的方法,我们再看看看,我们在监听到客户端连接的回调函数 server.on('request', function(req, res) {// do ....}) 中看到有两个参数 request 和 response ,
在这两个参数中,我们可以去获得用户的当前请求一些信息,比如头信息,数据等待,还可以向该次请求的客户端输出返回响应,下面我们一起看看它里面的内容
request 对象
参数request对象是 http.IncomingMessage 的一个实例,通过它 ,我们可以获取到这次请求的一些信息,比如头信息,数据,url参数等等
这里简单的列一下最常见的:
httpVersion: 使用的http协议的版本headers: 请求头信息中的数据url: 请求的地址method: 请求方式
response 对象
参数 response对象是 http.ServerResponse(这是一个由HTTP服务器内部创建的对象) 的一个实例,通过它 我们可以向该次请求的客户端输出返回响应。
response.writeHead(statusCode, [reasonPhrase], [headers]):向请求回复响应头,这个方法只能在当前请求中使用一次,并且必须在response.end()之前调用。statusCode: 一个三位数的HTTP状态码, 例如 404reasonPhrase:自行设置http响应状态码对应的原因短语headers:响应头的内容
write(chunk, [encoding]): 发送一个数据块到响应正文中 ,如果这个方法被调用但是response.writeHead()没有被调用,
它将切换到默认header模式并更新默认的headers。chunk可以是字符串或者缓存。如果chunk 是一个字符串,
第二个参数表明如何将这个字符串编码为一个比特流。默认的 encoding是’utf8’。end([data], [encoding]): 当所有的正文和头信息发送完成以后,调用该方法告诉服务器数据已经全部发送完成了。
这个方法在每次完成信息发送以后必须调用,并且是最后调用,如果指定了参数 data , 就相当于先调用response.write(data, encoding)之后再调用response.end()setHeader(name, value): 为默认或者已存在的头设置一条单独的头信息:如果这个头已经存在于 将被送出的头中,将会覆盖原来的内容。如果我想设置更多的头, 就使用一个相同名字的字符串数组
如:response.setHeader("Set-Cookie", ["type=ninja", "language=javascript"]);
看了那么多api,是时候实践一把了,我们再来对原来的代码进行一点改造~
// 导入http模块,url 模块
var http = require('http');
var url = require('url')
// 创建http server
var server = http.createServer();
server.on('request', function (req, res) {
// 将HTTP响应200写入response, 同时设置Content-Type: text/html:
res.writeHead(200, {
'Content-Type': 'text/html'
});
var urlObj = url.parse(req.url);
//根据用户访问的url不同展示不同的页面
switch (urlObj.pathname){
// 这是首页
case '/':
res.write('<h1>这是里首页</h1>');
break;
case '/user':
res.write('<h1>这里是个人中心</h1>');
break;
default :
res.write('<h1>你要找的页面不见了~</h1>');
break;
}
// 将HTTP响应的HTML内容写入response:
res.end();//这里就是告诉她可以停了
});
server.listen(8888,()=>{
console.log('Server is running at http://127.0.0.1:8888/')
}); 启动一下该js文件,并且通过不同的url不同的后缀,如 / 和 /user 去访问这个地址,看看浏览器的输出,应该已经变了。
这就是通过简单的的url处理,来实现的路由机制拉~
拓展:url 处理响应不同 html
当然这里我们再继续深入一下!结合 node 的文件系统(fs模块),使不同的url,直接读取不同的 html 文件,示例:
准备工作: 在当前文件目录下建立html文件夹, 并且新增文件 index.html与 user.html,内容自行发挥
var http = require('http');
var url = require('url');
var fs = require('fs');
var server = http.createServer();
// 读取我们当前文件所在的目录下的 html 文件夹
var HtmlDir = __dirname + '/html/';
server.on('request', function(req, res) {
var urlObj = url.parse(req.url);
switch (urlObj.pathname) {
case '/':
//首页
sendData(HtmlDir + 'index.html', req, res);
break;
case '/user':
//用户首页
sendData(HtmlDir + 'user.html', req, res);
break;
default:
//处理其他情况
sendData(HtmlDir + 'err.html', req, res);
break;
}
});
/**
* 读取html文件,响应数据,发送给浏览器
* @param {String} file 文件路径
* @param {Object} req request
* @param {Object} res response 对象
*/
function sendData(file, req, res) {
fs.readFile(file, function(err, data) {
if (err) {
res.writeHead(404, {
'content-type': 'text/html;charset=utf-8'
});
res.end('<h1>你要找的页面不见了~</h1>');
} else {
res.writeHead(200, {
'content-type': 'text/html;charset=utf-8'
});
res.end(data);
}
});
}
server.listen(8888);
console.log('Server is running at http://127.0.0.1:8888/');运行文件,切换url,程序会将不同的页面返回。大家自己去试试吧!
面试题
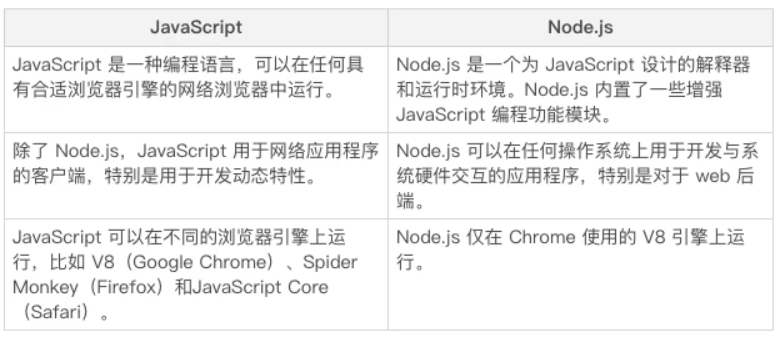
Node.js 与 JavaScript 有什么不同?
什么时候用 Node.js?
Node.js 是异步的、事件驱动的、非阻塞的和单线程的,使得它成为开发下面应用程序的完美候选:
- 实时应用程序,如聊天和提供实时更新的应用程序
- 将视频或其他多媒体内容流式传输给大量观众的流式应用程序
- 其他 I/O 密集型应用程序,如协作平台
- 遵循微服务架构的网络后端
Node. js的使用场景是什么?
高并发、实时聊天、实时消息推送、客户端逻辑强大的SPA(单页面应用程序)
readFile 和 createReadStream 函数有什么区别?
readFile 函数异步读取文件的全部内容,并存储在内存中,然后再传递给用户。
createReadStream 使用一个可读的流,逐块读取文件,而不是全部存储在内存中。
与 readFile 相比,createReadStream 使用更少的内存和更快的速度来优化文件读取操作。如果文件相当大,用户不必等待很长时间直到读取整个内容,因为读取时会先向用户发送小块内容。
const fs = require("fs");
fs.readFile("test.txt", (err, content) => {
console.log(content);
});REPL 是什么?
REPL 代表 Read Eval Print Loop,是一个虚拟环境,可以在其中轻松地运行编程语言。Node.js 带有一个内置的 REPL 来运行 JavaScript 代码,类似于我们在浏览器中用来运行 JavaScript 代码的控制台。
要启动 Node.js REPL,只需在命令行上运行 node,然后写一行 JavaScript 代码,就可以在下一行看到它的输出。
Node. js有哪些全局对象?
global、 process, console、 module和 exports。
Node. js的优缺点是什么?
优点如下:
(1) Node. js是基于事件驱动和无阻塞的,非常适合处理并发请求,因此构建在 Node. js的代理服务器相比其他技术实现的服务器要好一点。
(2)与 Node. js代理服务器交互的客户端代码由 JavaScript语言编写,客户端与服务端都采用一种语言编写。
缺点如下:
(1) Node .js是一个相对新的开源项目,不太稳定,变化速度快。
(2)不适合CPU密集型应用,如果有长时间运行的计算(比如大循环),将会导致CPU时间片不能释放,使得后续I/O无法发起
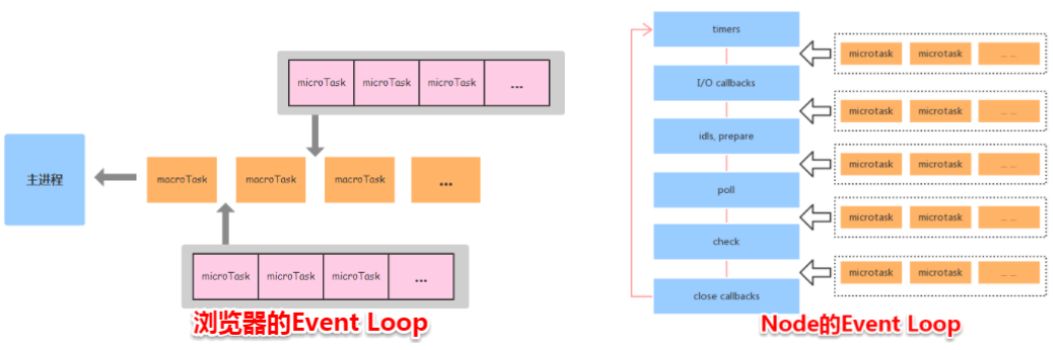
Node 与浏览器的 Event Loop 差异
浏览器环境下,microtask 的任务队列是每个 macrotask 执行完之后执行。而在 Node.js 中,microtask 会在事件循环的各个阶段之间执行,也就是一个阶段执行完毕,就会去执行 microtask 队列的任务。
额外内容
npm